Arithmetic mean
In mathematics and statistics, the arithmetic mean, often referred to as simply the mean or average when the context is clear, is a method to derive the central tendency of a sample space. The term "arithmetic mean" is preferred in mathematics and statistics because it helps distinguish it from other averages such as the geometric and harmonic mean.
In addition to mathematics and statistics, the arithmetic mean is used frequently in fields such as economics, sociology, and history, though it is used in almost every academic field to some extent. For example, per capita GDP gives an approximation of the arithmetic average income of a nation's population.
While the arithmetic mean is often used to report central tendencies, it is not a robust statistic, meaning that it is greatly influenced by outliers. Notably, for skewed distributions, the arithmetic mean may not accord with one's notion of "middle", and robust statistics such as the median may be a better description of central tendency.
Contents |
Definition
Suppose we have sample space  . Then the arithmetic mean
. Then the arithmetic mean 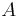 is defined via the equation
is defined via the equation
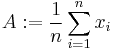 .
.
If the list is a statistical population, then the mean of that population is called a population mean. If the list is a statistical sample, we call the resulting statistic a sample mean.
Problems
The arithmetic mean may misinterpreted as the median to imply that most values are higher or lower than is actually the case. If elements in the sample space increase arithmetically, when placed in some order, then the median and arithmetic average are equal. For example, consider the sample space {1,2,3,4}. The average is 2.5, as is the median. However, when we consider a sample space that cannot be arranged into an arithmetic progression, such as {1,2,4,8,16}, the median and arithmetic average can differ significantly. In this case the arithmetic average is 6.2 and the median is 4. When one looks at the arithmetic average of a sample space, one must note that the average value can vary significantly from most values in the sample space.
There are applications of this phenomenon in fields such as economics. For example, since the 1980s in the United States median income as increased more slowly than the arithmetic average of income. Ben Bernanke, has speculated that the difference can be accounted for through technology, and less so via the decline in labour unions and other factors.[1]
Angles
Particular care must be taken when using cyclic data such as phases or angles. Naïvely taking the arithmetic mean of 1° and 359° yields a result of 180°. This is incorrect for two reasons:
- Firstly, angle measurements are only defined up to a factor of 360° (or 2π, if measuring in radians). Thus one could as easily call these 1° and −1°, or 1° and 719° – each of which gives a different average.
- Secondly, in this situation, 0° (equivalently, 360°) is geometrically a better average value: there is lower dispersion about it (the points are both 1° from it, and 179° from 180°, the putative average).
In general application such an oversight will lead to the average value artificially moving towards the middle of the numerical range. A solution to this problem is to use the optimization formulation (viz, define the mean as the central point: the point about which one has the lowest dispersion), and redefine the difference as a modular distance (i.e., the distance on the circle: so the modular distance between 1° and 359° is 2°, not 358°).
See also
|
|
Further reading
- Darrell Huff, How to lie with statistics, Victor Gollancz, 1954 (ISBN 0-393-31072-8).
External links
Reference list
- ↑ Ben S. Bernanke. "The Level and Distribution of Economic Well-Being". http://www.federalreserve.gov/newsevents/speech/bernanke20070206a.htm. Retrieved 23 July 2010.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||